






EDICIÓN DE TEXTO EN HTML
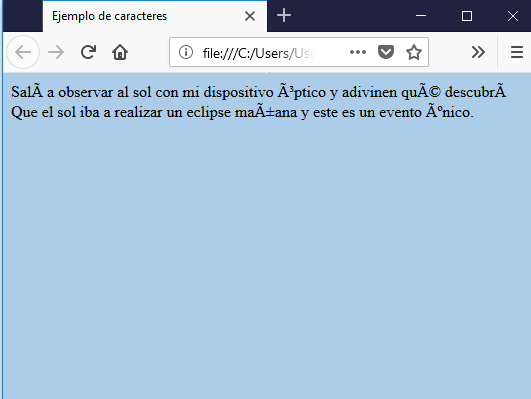
HTML es un lenguaje que fue creado en Estados Unidos y sus caracteres básicos son los de la lengua inglesa, por ende, caracteres como la Ñ o las tildes no son interpretadas correctamente por el navegador. Como lo vemos en el siguiente código:
<head>
<title>Ejemplo de caracteres</title></head>
<body bgcolor= "#abcde9">
Salí a observar al sol con mi dispositivo óptico y adivinen qué descubrí Que el sol iba a realizar un eclipse mañana y este es un evento único. <br> </body></html>
Existen una serie de códigos para señalar cuando es una ñ o una letra con tilde, estos se ven a continuación:
|
Carácter |
Código |
|
Ñ - ñ |
Ñ - ñ |
|
Á - á |
Á - á |
|
É - é |
É - é |
|
Í - í |
Í - í |
|
Ó - ó |
Ó - ó |
|
Ú - ú |
Ú - ú |
Vamos a observar un ejemplo de escritura HTML con este tipo de código:
<html>
<head><title>Ejemplo de carácteres </title></head>
<body bgcolor= "#abcde9">
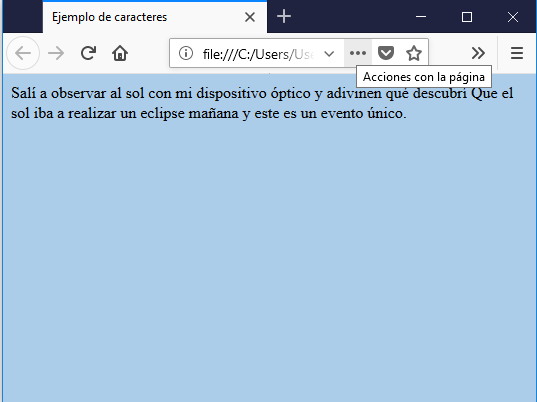
<br> El siguiente texto tiene diferentes acentos: <br>
Salí a observar al sol con mi dispositivo óptico y adivinen qué descubrí Que el sol iba a realizar un eclipse mañana y este es un evento único.
<br></body></html>
El resultado es el siguiente:
Debido a la complejidad del sistema y a que no solamente el español presentaba problemas, con estos símbolos se determinó que se debía utilizar una terminología especial de caracteres para cada lenguaje, ejemplo el español, el chino, el japonés, entre otros.
Este tipo de agrupación de caracteres se denominó UTF, y dependiendo del idioma los navegadores disponen del traductor de símbolos y ya no es necesario colocar cada código de letras especiales en cada línea del texto.
Para consultar los tipos de formato de texto pueden observar el siguiente enlace:
https://www.gestiweb.com/?q=content/problemas-html-acentos-y-e%C3%B1es-charset-utf-8-iso-8859-1
El UTF según su sigla es Unicode Transformation Format, pero que es Unicode, pues es un estándar de codificación de caracteres diseñado para facilitar el tratamiento informático, transmisión y visualización de textos de múltiples lenguajes y disciplinas técnicas, además de textos clásicos de lenguas muertas. El término Unicode proviene de los tres objetivos perseguidos: universalidad, uniformidad y unicidad. *1.
El UTF permite realizar una transformación de los diversos caracteres de los lenguajes existentes el sistema UTF más utilzado es el UTF-8, sus características especiales son:
Es capaz de representar cualquier carácter Unicode.
Usa símbolos de longitud variable (de 1 a 4 bytes por carácter Unicode).
Incluye la especificación US-ASCII de 7 bits, por lo que cualquier mensaje ASCII se representa sin cambios.
Incluye sincronía. Es posible determinar el inicio de cada símbolo sin reiniciar la lectura desde el principio de la comunicación.
No superposición. Los conjuntos de valores que puede tomar cada byte de un carácter multibyte, son disjuntos, por lo que no es posible confundirlos entre sí. *2
Para utilizar este sistema debemos declararlo en el encabezado HEAD de HTML. Veamos con el siguiente ejemplo como se desarrollaría el ejemplo 1, pero con el parámetro de UTF-8
<!doctype html>
<head>
<meta http-equiv="Content-type" content="text/html; charset=utf-8" />
<title>Imagen de fondo HTML</title></head>
<body bgcolor= "#abcde9">
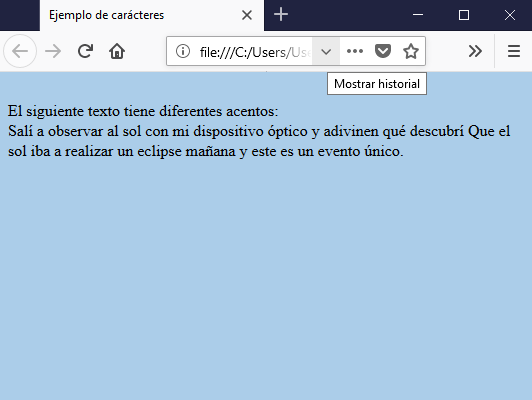
Salí a observar al sol con mi dispositivo óptico y adivinen qué descubrí Que el sol iba a realizar un eclipse mañana y este es un evento único. <br> </body></html>
El resultado es el siguiente:
La primera etiqueta indica al navegador que es un documento de HTML, la etiqueta:
<meta http-equiv="Content-type" content="text/html; charset=utf-8" />
Me permite cargar todos los caracteres del lenguaje español y de esta manera facilitar el desarrollo de las páginas web.
Reto Crear una página en la cual muestres una imagen de fondo y un poema o un fragmento escrito de un libro u obra literaria, grabar la página web como textoyfondo.html
